Most of the time our world presents us with a multitude of sounds simultaneously. We automatically accomplish the task of distinguishing each of the sounds and attending to the ones of greatest importance. Unless there is something we want to hear but cannot, we probably do not consider all the sounds we do not hear in the course of a day.
It is often difficult to hear one sound when a much louder sound is present. This process seems intuitive, but on the psychoacoustic and cognitive levels it becomes very complex. The term for this process is masking, and it is probably the most researched phenomenon in audition (Zwislocki 1978).
Definitions of masking differ according to what field it is being related. In order to gain a broad and thorough understanding of this phenomenon we can survey the definition and its accompanying explanation from several views. Masking as defined by the American Standards Association (ASA) is the amount (or the process) by which the threshold of audibility for one sound is raised by the presence of another (masking) sound (B.C.J. Moore 1982, p. 74). For example, a loud car stereo could mask the car's engine noise. The term was originally borrowed from studies of vision, meaning the failure to recognize the presence of one stimulus in the presence of another at a level normally adequate to elicit the first perception (Schubert 1978, p. 63).
Critical Bands
To determine this threshold of audibility, an experiment must be performed. A typical masking experiment might proceed as follows. A short, about 400 msec, pulse of a 1,000 Hz sine wave acts as the target, or the sound the listener is trying to hear. Another sound, the masker, is a band of noise centered on the frequency of the target (the masker could also be another pure tone). The intensity of the masker is increased until the target cannot be heard. This point is then recorded as the masked threshold (Scharf 1975). Another way of proceeding is to slowly widen the bandwidth of the noise without adding energy to the original band. The increased bandwidth gradually causes more masking until a certain point is reached, at which no more masking occurs. This bandwidth is called the critical band (Bregman 1990). We can keep extending the masker until it is full- bandwidth white noise and it will have no more effect than at the critical band.
As figure 1 shows, critical bands grow larger as we ascend the frequency spectrum. Conversely, we have many more bands in the lower frequency range, because they are smaller. It will become important later in the discussion to remember that the size of the critical bands is not constant across the frequency range.
Critical bands seem to be formed at some level by auditory filters (Schubert 1978). These filters act similarly to the conventional frequency-specific electronic devices that parse the audio spectrum. There is only sparse evidence for the process of the auditory filter; it is not clear whether separation occurs in the inner ear or at some higher level. There is no agreement as to the specific number of critical bands active simultaneously. Critical bands and their center frequencies are continuous, as opposed to having strict boundaries at specific frequency locations. Therefore, the filters must be easily variable. Use of the auditory filter may be the unconscious equivalent of our willfully focusing on a specific frequency range.
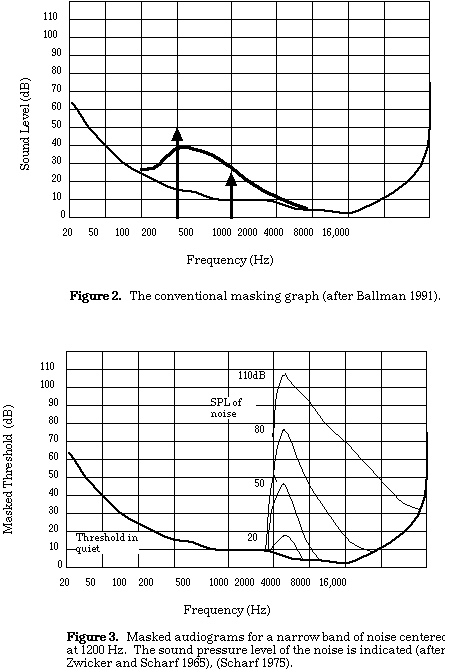
In general, low sounds mask higher sounds, as we can see from figure 3. There is little masking lower than the center frequency of the noise band. A general rule displayed by this graph is that masking tends to occur between sounds that are close together in frequency. It is also apparent that above 20 dB, for every increase in masker energy there is a direct rise in the threshold of the target. Conveniently, different center frequencies share the same audiogram as do pure tone maskers. The physiological reasons for the masking of high tones by low tones are worth pursuing at this point.
By way of transduction, the basilar membrane in our inner ear vibrates in response to sound. Low frequencies displace the basilar membrane much more: the distance from stapes (one of the three bones in the middle ear) is about 30mm at 25 Hz compared to 20mm at 800 Hz (Scharf 1975). Additionally, as frequency increases, the location of maximum displacement along the basilar membrane moves from the farthest section of the inner ear (helicotrema) toward the middle ear (to the stapes and the oval window). Higher frequencies must therefore be of greater intensity to overcome the dominance, both spatially and quantitatively, of the low notes over the basilar membrane. Of this knowledge Scharf (1975) states,
The spatial representation of frequency on the basilar membrane is perhaps the single most important piece of physiological information about the auditory system, clarifying many psychophysical data, including the masking data and their asymmetry (p. 130).We often use visual analogies to aid in learning. The conventional graph showing one tone masking another (see figure 2) may be an effective visual analogy when trying to comprehend the masking effect. The thin line represents our hearing threshold when no sounds are present. A 500 Hz tone at 25 dB would be within our threshold of hearing. When a masking tone is present, a 200 Hz tone at 50 dB in this case, the threshold of audibility is altered (represented by the thicker line on the graph) so that the 500 Hz tone is masked.
Unfortunately, this graph only describes a surface understanding of the cognitive processes. The graph implies that once a masking tone is present we are biologically incapable of receiving the target tone. In reality, we still sense, physiologically, the masked tone, but it cannot be audibly recognized. Albert S. Bregman offers us a more neurologically-sound analogy. He asks us to imagine hiding a red spot on a white canvas by painting the entire canvas red. The spot is still there, but it is impossible to distinguish. He continues,
You can think of a masker as something that fills in the background in such a way that there is no longer any spectral shape defined against the white canvas of silence. The signal is still there, but it is camouflaged. Masking, then, is the loss of individuality of the neural consequences of the target sound, because there is no way of segregating it from the effects of the louder tone (Bregman 1990, p. 392).
Non-Simultaneous Masking
The ASA definition of masking does not address non-simultaneous masking. Sometimes a signal can be masked by a sound preceding it, called forward masking, or even by a sound following it, called backward masking. Forward masking results from the accumulation of neural excitation, which can occur for up to 200 msec. In other words, neurons store the initial energy and cannot receive another signal until after they have passed it, which may be up to 200 msec. Forward masking effects are slight: maskers need to be within the same critical band and even then do not have the broad masked audiograms of simultaneous masking. Likewise, backward masking only occurs under tight tolerances.
There is a paradoxical effect in forward masking where masking is reduced as masker bandwidth is increased. The scene-analysis explanation offered by Bregman (1990) argues that narrow-band noise sounds more like the pure tone target than does wide-band noise. We instantaneously compute the global quality of the wider noise and sense that, when the masker is turned off, not all frequencies were silenced together, whereas a narrow-band would provide fewer frequencies for comparison.
Central Masking and Other Effects
Another way to approach masking is to question at what level it occurs. Studies in cognition have shown that masking can occur at or above the point where audio signals from the two ears combine. The threshold of a signal entering monaurally can be raised by a masker entering in the other ear monaurally. This phenomenon is referred to as central masking because the effect occurs between the ears.
Spatial location can have a negative effect on masking. Many studies have been performed in which unintelligible speech can be understood once the source is separated in space from the interference (Bregman 323). The effect holds whether the sources are actually physically separated or perceptually separated through the use of interaural time delay.
Asynchrony of the onset of two sounds has shown to help prevent masking, as long as the onset does not fall within the realm of non-simultaneous masking. Each 10 msec increase in the inter-onset interval was perceived as being equal to a 10 dB increase in the target's intensity (Bregman 1990). Experiments by Rasch revealed that musicians in an ensemble had typical deviations of onset from 30 to 50 msec, unwittingly providing their own solution to masking effects. Incidentally, computer music sequencers would do well to provide the feature of differing onset between tracks, ideally modeling the deviation after human performers.
Fusion
The concept of fusion must be included in any intelligent discussion of masking because the two are similar and often confused. In both cases, the distinct qualities of a sound are lost, and both phenomena respond in the same manner to the same variables (Bregman 1990). In fusion, like in masking, the target sound cannot be identified, but in fusion the masker takes on a different quality. Bregman explains,
...the typical masking experiment does not necessarily provide a measure of perceptual fusion. In a fusion experiment, on the other hand, listeners are asked whether they can or cannot hear the target in the mixture or, even better, to rate how clearly they can hear the target there. What we want to know is whether the target has retained its individual identity in the mixture (Bregman 1990, p. 316).Fusion takes into consideration interactive global effects of two sound sources on each other, instead of trying to reduce the situation to two separate and distinct entities. Masking experiments are concerned with finding the threshold at which the target cannot be identified, ignoring the effect of the target on the masker. Earl D. Schubert (1978) states,
...it is remarkable that throughout the subsequent history of masking experiments seldom is any differentiation made between those instances where a recognizable percept was missing and those where simply some change was discernible. (p. 64).We will see later what possible implications for audio technology purposes the emphasis on masking research, as opposed to fusion, may hold.
Perceptual Coding
Use of psychoacoustic principles for the design of audio recording, reproduction, and data reduction devices makes perfect sense. Audio equipment is intended for interaction with humans, with all their abilities and limitations of perception. Traditional audio equipment attempts to produce or reproduce signals with the utmost fidelity to the original. A more appropriately directed, and often more efficient, goal is to achieve the fidelity perceivable by humans. This is the goal of perceptual coders.
Although one main goal of digital audio perceptual coders is data reduction, this is not a necessary characteristic. As we shall see, perceptual coding can be used to improve the representation of digital audio through advanced bit allocation. Also, all data reduction schemes are not necessarily perceptual coders. Some systems, the DAT 16/12 scheme for example, achieve data reduction by simply reducing the word length, in this case cutting off four bits from the least-significant side of the data word, achieving a 25% reduction.
Out of a desire for simplicity, the first digital audio systems were wide-band systems, tackling the entire audio spectrum at once. Presently, perceptual coders are multiband systems, dividing up the spectrum in a fashion that mimics the critical bands of psychoacoustics (Ballman 1991). By modeling human perception, albeit in an elemental way, perceptual coders can process signals much the way humans do, and take advantage of phenomena such as masking. While this is their goal, the process relies upon an accurate algorithm. The ISO/MPEG Layer II coding scheme has been judged by a several organizations to be indistinguishable from linear 16-bit recordings (Pohlman 1993b). If present commercial systems sound inadequate, it is not the fault of perceptual coding but of the particular algorithm applied.
Audio Processing Technology, Ltd. has developed a perceptual coding scheme of interest. While using adaptive delta pulse code modulation (ADPCM), the frequency spectrum is divided into four bands in order to remove unperceivable material. Once a determination is made as to what can be discarded, the remainder is allocated the available number of bits. This process is called dynamic bit allocation. Because bits are not wasted on masked material, they can be distributed in greater quantity to the rest of the signal. Using dynamic bit allocation, a 16 bit coder can achieve a broadband dynamic range equivalent of 18 to 20 bits of linear coding.
The Digital Compact Cassette (DCC) developed by Philips is one of the first commercially available forms of perceptually coded media. It achieves a 25% data reduction through the use of the Precision Adaptive Sub-band Coding (PASC) algorithm. The algorithm contains a psychoacoustical model of masking effects as well as a representation of the minimum hearing threshold. The masking function divides the frequency spectrum into 32 equally spaced bands. Sony's ATRAC system for the MiniDisc format is similar.
Shortcomings
In every masking study this author has encountered, either a band of noise or a pure tone was used as the masker, never music. So how does PASC purport to deal with musical material? Ken Pohlman (1992a) reports that, it was determined that tone curves are valid models for music coding. Nevertheless, future research may result in better masking curves (p.17). This author agrees, for there is a great deal of dissimilarity between human masking effects and the current algorithms. Zwislocki (1978) warns,
It should be evident that masking relationships are complex and that extrapolations from one masking situation to another should be made with great caution. In particular, masking produced by narrow-band noise is not directly predictable from masking experiments with wide-band noise, and vice-versa (p. 295).PASC is considered a conservative model because it does not assume masking will fall within its preset bands but at their edges (Pohlman 1992b). Its bands are immovable and of equal length. Human masking on the other hand is a more global approach, processing tones with frequencies across several bands with movable, continuous critical bands of increasing size. The ATRAC scheme used in Sony's Mini-Disc more closely models critical bands with larger bands on the high frequency end (Pohlman 1993a). Present schemes also have no idea of fusion, and may remove a sound it considers masked when that sound may have had an effect on another sound. It is not clear whether today's perceptual coders take spatial and central masking into account, which would require examining both stereo channels together. It is also unclear how the native spatial material embedded in the signal is affected (Ballman 1991).
To its credit, the PASC system looks at 8 msec pieces of the signal at a time, thus avoiding complications associated with onset asynchrony, which begins affectation at 10 msec. From the absence of functions to address non- simultaneous masking we can infer one of two things: either the system is not intended to be that exacting, or the designers considered non-simultaneously masking too insignificant to acknowledge.
Perceptual coders still have room for improvement but are headed in what seems to be a more intelligent direction. The algorithms are not perfect models of human perception and cognition. Of course, while the modeling of a perceptual coder could be over-engineered in the spirit of cognitive science in order to learn more about human cognition, all that is necessary in perceptual coding is to develop an algorithm that operationally corresponds to human auditory perception, not one that physically copies it.
The Future
It is probable that all future coding schemes that make any claim to sophistication will make use of psychoacoustical principles. While the present commercial systems, PASC and ATRAC, were instituted in the interest of economy of tape usage, there are other valuable functions for perceptual coders. Digital audio workstations, presently requiring large amounts of hard disk space and fast access times, are a prime example of where perceptual coding is needed. A 1.2 gigabyte drive could presently store 120 minutes of linear, 16-bit stereo digital audio. Assuming the 25% efficiency of PASC, 150 minutes could be stored using perceptual coding, the equivalent of a 1.5 gigabyte drive. Additionally, the perceptually coded material may sound better because of dynamic bit allocation. If the coding was performed in real time, as some are, then the speed of transfer between the central processing unit and the disk drive would also be increased.
Other applications include stand-alone converter modules for conversion to any media and, eventually, software encoders. The need for standardization soon becomes apparent, and hopefully it will be met.
Next Section:
Future audio and Internet developments:
Client-Server Systems
Audio on The Internet